AI Workshop for Learning Center Leaders
A practical guide on how LLMs work, their pitfalls, and how you can use them effectively at your center.

As a Learning Center leader, you wear many hats: managing a team, balancing budgets, marketing to students, and more. The conversation around Artificial Intelligence (AI) can feel like just one more thing to add to your plate.
That said, I believe AI can both be a useful tool in center management and present an opportunity to help students and tutors learn key skills that aren't being taught. This webinar aims to explore what Large Language Models (LLMs) are, why they sometimes make things up (hallucinating), and how you can use them for practical tasks at your center.
Here is a text summary of the workshop above.
LLMs Under the Hood
First, let's clarify some terms. Artificial Intelligence (AI) is a broad umbrella for computers performing human-like tasks. This could be a security camera identifying a threat (computer vision) or a robot folding laundry (robotics). Large Language Models (LLMs), like ChatGPT, Gemini, and Claude, are a specific type of AI focused on text.
At their core, LLMs are prediction engines. They take text in, run it through a complex mathematical model (a neural net), and predict the next most likely word.
"They really just predict one word at a time... LLMs don’t have a sense of correctness or logic. They say the thing that sounds the most right, the thing that is likeliest that someone would say in that instance.”
This process repeats for every single word in a response. When you ask, "What are the best places to visit in France?" it predicts "France," then adds that to the input and predicts "has," then "many," and so on, word by word. This is a critical concept because it explains why models hallucinate, why they SOUND so correct and confident and coherent, when sometimes saying something totally wrong (or something meaningless). Their entire design is around putting highly likely words one after another, based on what was in it’s training data.
It's also helpful to think of a specific model, like GPT-4, as a static "thing." The process of creating it, called training, is a massive, discrete event that occurs and is done. Once trained, the model is largely finished and its knowledge is stuck in time, much like a person whose core knowledge and tendencies are set.
How an LLM Is Trained
The training process is what turns a bunch of code into something that can write an essay or explain a concept. It’s essentially a process of compressing vast amounts of information—often, a significant portion of the public internet—into a model that can recognize and replicate patterns. This happens in three main stages.
1. Pre-Training: Learning from the Internet
The first and largest stage is pre-training. In this phase, the model is fed a massive dataset of text. Imagine taking all of Wikipedia, millions of books, and countless websites and glueing them together into one giant document.

Before the model can "read" this text, the text must be converted into numbers, a process called tokenization.
Like what you're reading?
Subscribe to our newsletter and receive new posts directly to your inbox.
"Computers see in numbers, not in words. So, you can kind of think of it like words, but it does translate… these words, into numbers, and the computer can digest the numbers well."
A "token" is a common sequence of characters. It could be a whole word like "capital" or a part of a word like "ing". The goal is to create a vocabulary of around 100,000 unique tokens that can represent the entire training dataset. The phrase "The capital of France is Paris\!" might be broken into tokens like [The], [capital], [of], [France], [is], [Paris], [!]. Each of these tokens is assigned a number.
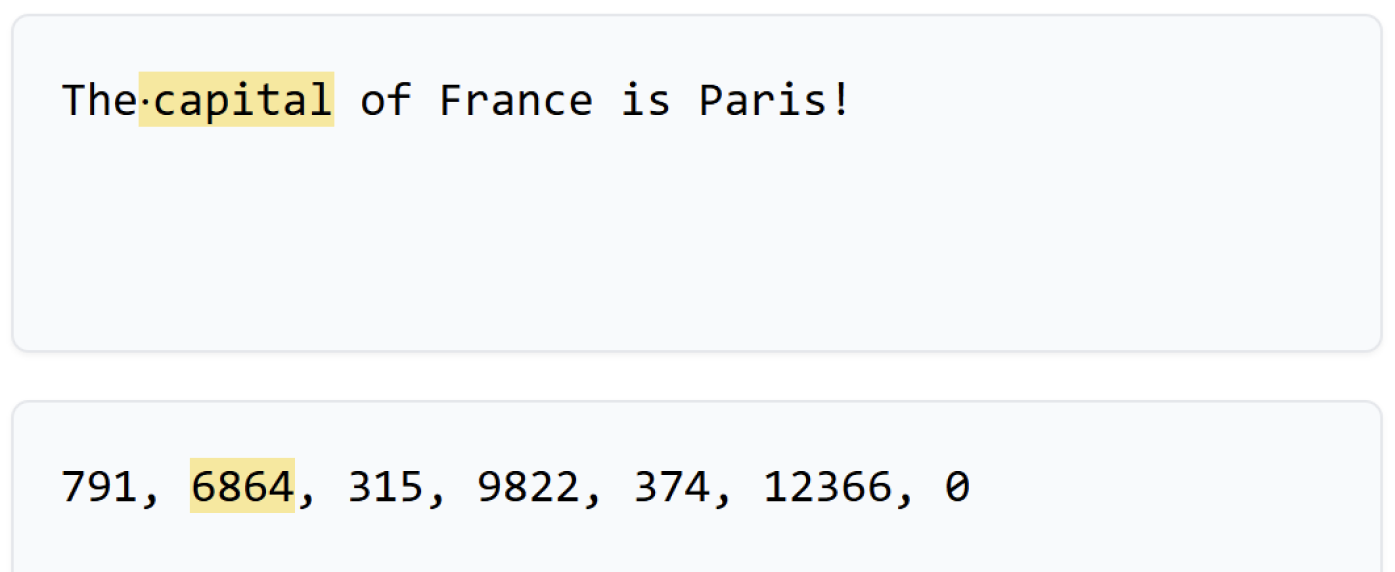
Once the entire internet is tokenized, the training begins. The model is shown a sequence of tokens and asked to predict the next one. It learns the statistical relationships between them. It notices that the token for "France" is often followed by the token for "Paris," or that the token for a comma is frequently followed by the token for "but." It does this billions of times, slowly tweaking its internal network to get better and better at predicting the next token in any given context.
2. Post-Training: Fine-Tuning & Reinforcement Learning
After pre-training, the model is a powerful but raw tool. The next steps refine it.
- Fine-tuning involves training the model on more specific, high-quality data. For example, it might be fed thousands of chemistry problems and their correct solutions to become better at academic tasks.
- Reinforcement Learning with Human Feedback (RLHF) is where humans get involved. People ask the model questions and then rate its answers. Was the answer helpful? Was it harmful? Was it accurate? This feedback teaches the model to be a more useful and safe assistant, rather than just a text predictor.
Why LLMs "Hallucinate"
This brings us to one of the most talked-about problems with LLMs: hallucinations, or when the model confidently states something that is completely false. Understanding the training process makes it clear why this happens. The model's fundamental goal is not to be correct, but to sound coherent. It's designed to predict the statistically most likely next word based on how people talk and write in it’s training data. It’s goal is NOT to “be correct”.
To see this in action, you can use what’s called a "base model"—one that has only been pre-trained, without the safety layers from fine-tuning and reinforcement learning. Check out the webinar recording for a fun live demo of this.
If you ask a base model, "Who is Tom Cruise?" it will pull from its training data and correctly identify him as an actor, mentioning his films. The internet is full of information about Tom Cruise, so the statistically likely words form a factual answer.
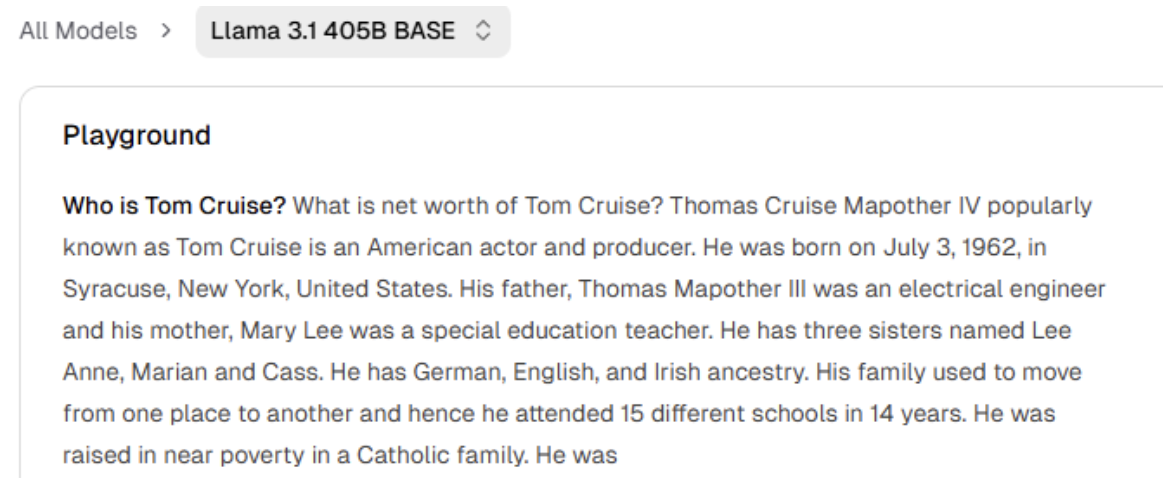
But if you ask about a person who doesn't exist, like "Who is Cristoph Montrose?", the base model won't say "I don't know," because it is designed to predict the most likely next word, even if the likelihood isn’t very high. It will default to something that sounds coherent and proceed to provide some kind of biography or profile.
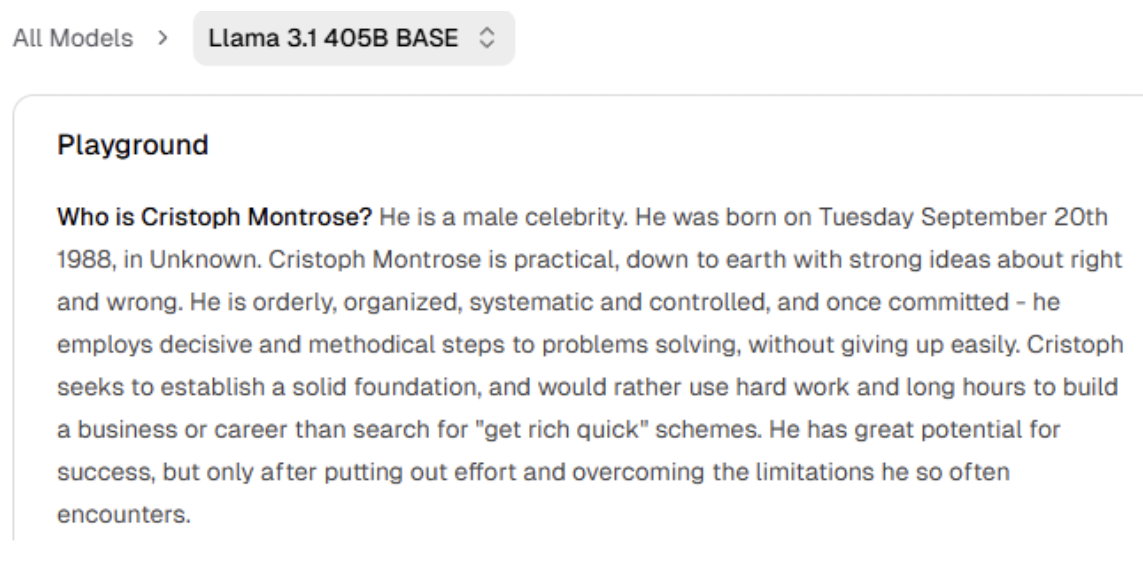
It might invent a profession, a backstory, and even legal troubles, with each word being the most statistically likely successor to the last. It doesn’t have some threshold of certainty in it’s word by word predictions where it eventually says something like “I don’t know”, but rather tries its best, all the time.
Modern models like ChatGPT have been trained to say "I don't know," using post-training techniques like fine tuning and reinforcement learning, but the underlying behavior is still there. This is why a healthy skepticism is essential.
So that’s enough about underlying theory. This can help you build appropriate skepticism, but isn’t all that practical beyond this. Something that can be practical? Vibe coding.
Practical Use 1: Building Tools with "Vibe Coding"
One of the most interesting AI developments is "vibe coding"—using natural language to build simple software applications. Tools like Lovable and Replit allow you to describe an app you want, and the AI will generate the code for you.
Jin, the Tutoring Center Coordinator at Las Positas College, provides a great example. For years, he wanted a public-facing calendar on his center's website to show students the drop-in tutoring schedule.
"I've been bugging Ben to make me a calendar that I can put on my website, and he hasn't done it, so I did it myself."
Using Lovable, Jin built a fully functional, sortable drop-in calendar that is now live on his center's website. Students and faculty can filter by subject (e.g., Econ 1) and see exactly who is available for drop-in help, without having to log into another system.
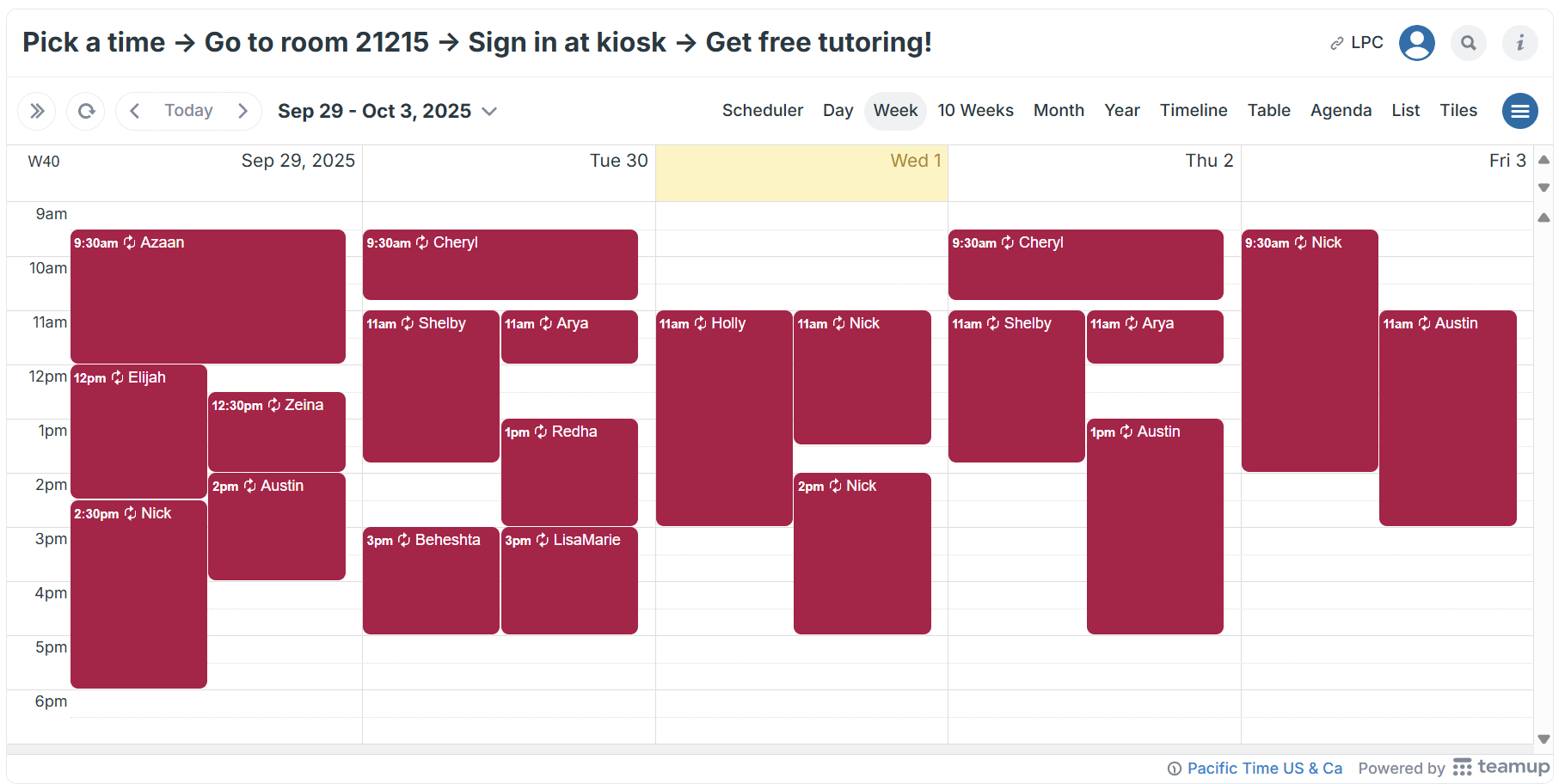
He also demonstrated how quickly a new tool could be created. To get student feedback, he considered paying for a "happy or not" kiosk service. Instead, he gave Lovable a simple prompt.
"I've got a kiosk ready to go, like, within, like, you know, 5 minutes... I would have paid $700 a year for this. And I built it in 5 minutes."
For a Learning Center Director, this opens the door to creating small, custom tools that solve specific problems—a feedback form, a simple resource directory, a tutor availability checker—without needing a large budget or official IT support.
This theme of custom applications to solve small, discrete tasks will be a common trend in real-world AI value. Another forum for this is in automating administrative workflows using Zapier.
Practical Use 2: Automating Administrative Tasks with Zapier
Beyond building new tools, AI can automate the small, recurring administrative tasks that consume your time. Tools like Zapier allow you to connect different software applications and create automated workflows. For example, you can set a "trigger" (like a new entry in a Google Form) and an "action" (like creating a calendar event).
Where AI makes this powerful is by becoming a step in that workflow. It can read, summarize, and make decisions based on unstructured text.
Consider managing your email inbox. You could create a workflow with the following steps:
- Trigger: A new email arrives in your Outlook or Gmail inbox.
- AI Action: The email content is sent to an AI model with a prompt like: "Read this email. Determine if it contains a deadline or appears urgent for any other reason. If so, output the word 'Urgent'."
- Final Action: If the AI outputs "Urgent," Zapier automatically applies an "Urgent" label to that email in your inbox.
This same logic can be applied to many common learning center tasks:
- Tutor Hiring: When a student submits an application form, a workflow could trigger an AI step to read their qualifications and sort them into tiers, then create a folder for them in Google Drive and send a confirmation email.
- Student Feedback: When feedback is submitted, an AI could categorize it (e.g., "Positive," "Complaint," "Suggestion") and add it to a corresponding spreadsheet.
This area is evolving quickly. New AI-powered browsers are emerging that can act on your behalf on any website. You could tell it, "Go to our scheduling system, find all tutors who are qualified for CHEM 101, and draft an email to them about a new training opportunity." The browser would navigate the site, gather the information, and draft the email for you. This moves AI from a simple writing assistant to a true administrative partner.
Navigating the New Landscape with Your Tutors
Of course, the most pressing question for many directors is how to handle AI with students and tutors, especially when institutional policies are still being formed. Many centers find themselves in a weird place where faculty have different rules and the college has not set a clear policy.
Promoting AI literacy amongst tutors appears to be a productive and safe next step for learning centers that can provide needed knowledge, both to tutors and students.
"The approach we've all agreed on right now is promoting AI literacy. Like, our tutors need to be literate to understand... both to arm themselves, and also if a student wants to come in and talk about it."
The goal isn't to be for or against AI, but to equip tutors with a solid understanding of how these tools work. By understanding that LLMs are powerful pattern-matchers, not truth-tellers, tutors can help students use them more critically.
"We're really trying to help the tutors understand it so that if a student comes in and is using it already, we can talk with them with some level of understanding of some of the pitfalls, some of the worries, as well as some of the beneficial ways to use it."
The concepts in this article—word-by-word prediction, tokenization, and the cause of hallucinations—are good starting points for building literacy. Our plan is to expand upon this educational material with an increased focus on how to use AI for effective learning. Learning center leaders can distribute this content amongst the students on their campus.
Feedback and input welcome on future topics - please email be at ben.h@penjiapp.com.


.jpg)





